开云体育 让大模子边想边说: 这篇著作把「何时启齿」变成可学习计策


导语:推理模子的「千里默税」该若何解?
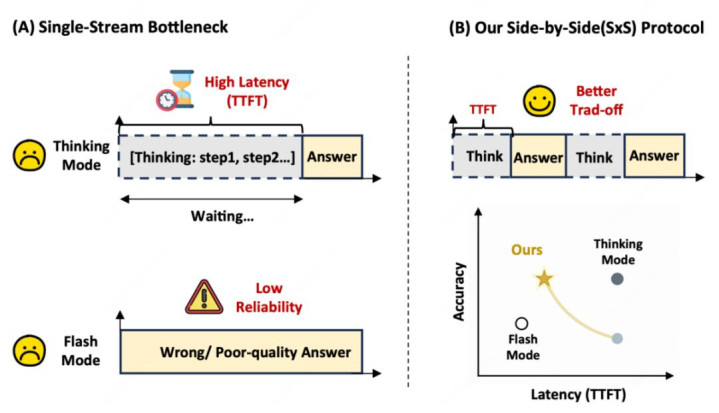
用过推理型大模子的东说念主,大略率都熟识这种体验:模子似乎在讲求念念考,但屏幕上万古辰莫得着实有用的实质;要是让它一初始就输出,又很容易出现仓促判断,后头的推理还要被早期造作牵着走。
这恰是论文 When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning 试图搞定的问题。作家把这种矛盾称为单流自转头接口下的 “silence tax”(千里默税):在传统单一可见流里,每个生成 token 既更新模子情景,又组成不可撤离的公开承诺。模子多想瞬息,用户就多等瞬息;模子早说小数,又可能过早承诺。
为此,来自纽约州立大学石溪分校、浙江大学、威廉玛丽学院、伊利诺伊大学香槟分校、英属哥伦比亚大学、香港汉文大学、以及复旦大学的磋议东说念主员建议 Side-by-Side(SxS)Interleaved Reasoning(并排式交错推理),把 “何时涌现实质” 变成一个可学习的决议。模子不错在归拢个自转头坎坷文里轮流实施两类动作:络续念念考,或涌现仍是被现时推理撑持的谜底片断。这么一来,流式生成不再仅仅前端展示计策,而变成了模子自身学到的 “涌现计策”。

论文标题:When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning
机构:Stony Brook University、浙江大学、William & Mary、UIUC、UBC、香港汉文大学、复旦大学
会议:ICML 2026
一句话轮廓这篇论文
SxS Interleaved Reasoning 让大模子在推理过程中学会 “边想边说”:只好当谜底片断仍是被现时推理前缀撑持时,才把它当作用户可见实质披浮现来;其余推理络续保留在归拢坎坷文中,匡助模子完成后续推理。
这不是圣洁地让模子更快输出第一个 token,也不是饱读吹它用 “我正在念念考” 之类的空论填充恭候时辰。论文关注的是实质延伸,也便是用户什么时候能看到着实和任务有关、且有依据的实质。
为什么 “快点输出” 不是谜底
现时大模子的流式交互庸碌默许一个盘算:模子生成什么,用户就立即看到什么。这种盘算圣洁、褂讪,也便捷部署,但它把两个正本不同的问题绑在了沿途。
第一,生成 token 是模子情景更新的一部分,后续推喜悦基于已生成前缀络续张开。
第二,生成 token 亦然面向用户的公开承诺,一朝展示出来,就会戒指后续恢复不成松驰推翻。
在圣洁问答里,这个耦合问题不昭着;但在数学、科学问答、代码推理等任务里,模子连接需要较长的中间推理。若先竣工念念考再恢复,用户会资格万古辰千里默;若一初始就把中间想法或候选谜底娇傲出来,造作前缀又可能形成 “过早承诺”。
论文的关键判断是:真偶合得优化的不是 Time to First Token, TTFT(首 token 延伸)这种系统层面的目的,而是 “第一个有用实质何时出现,以及两次有用更新之间阻隔多久”。这亦然 SxS 后续评测里使用 ARI、ABO、AIRW 等实质延伸目的的原因。
中枢本事:把输出分红
“念念考” 和 “涌现” 两种动作
SxS 的盘算很径直:模子仍然是轨范自转头生成,乐动体育世界杯中国官网首页不需要第二个模子、第二套掩藏情景或颠倒的推理架构;不同之处在于,它在生成流里通过轻量标签鉴识两类 token。
think(念念考动作):用于络续里面推理,不径直当作用户可见谜底涌现。
speak(涌现动作):用于涌现用户可见实质,这些实质必须被现时推理前缀撑持。
不错把它默契成一种 “可控可见性” 的单流生成。通盘实质仍在归拢坎坷文里,因此模子不会丢失前边推理;但用户看到的,仅仅模子聘请涌现的谜底流。
这带来的变化很首要:模子不必在 “千里默到终末” 和 “赶紧冒险恢复” 之间二选一。它不错先涌现一个仍是被现时推理撑持的谜底前缀或部分谜底,再络续推理剩余部分,随后迟缓补全最终恢复。
考验经由:先学会阵势,
再用 RL 找回推明智商
博亚体育中国官网在线入口论文的考验分红两个阶段,中枢观点是幸免一个常见反作用:要是只奖励早输出,模子可能学会说谣言;要是只学交错阵势,模子准确率又可能下滑。
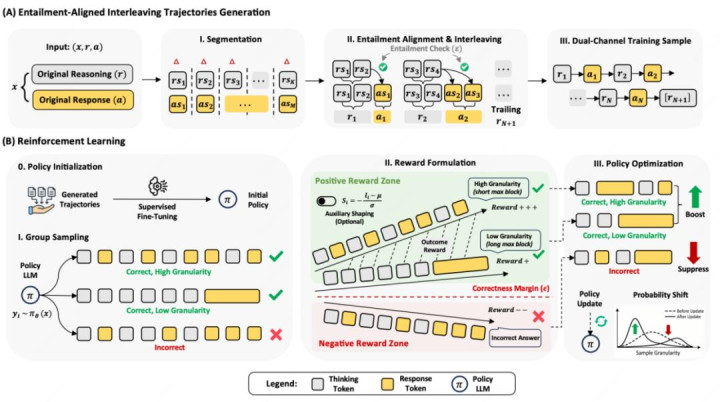
第一步,构造蕴含对皆的交错轨迹 (entailment-aligned interleaved trajectories)。作家从轨范的 prompt、reasoning、response 三元组启航,把推理和谜底都切分红片断,再判断某个谜底前缀是否仍是被现时推理前缀撑持。只好被撑持的谜底片断才会被放进 speak。
第二步,用 SFT 学会双动作语义。SFT 让模子先掌捏 think /speak 的基本阵势,开云体育知说念什么时候络续推理,什么时候涌现实质。
第三步,用 GRPO 作念 RL 规复推感性能。因为交错阵势会改变生因素布,SFT 后准确率可能下落;RL 阶段用收尾正确性信号把模子拉回高质地推理,同期保留涌现节拍。
这套经由的一个实用点是:它莫得把 “早输出” 写成硬章程,而是把 “有依据地早涌现” 当作监督和优化观点。换句话说,早不是目的,早且可撑持才是目的。
本质收尾:更短的可见恭候,
更好的准确率 — 延伸量度
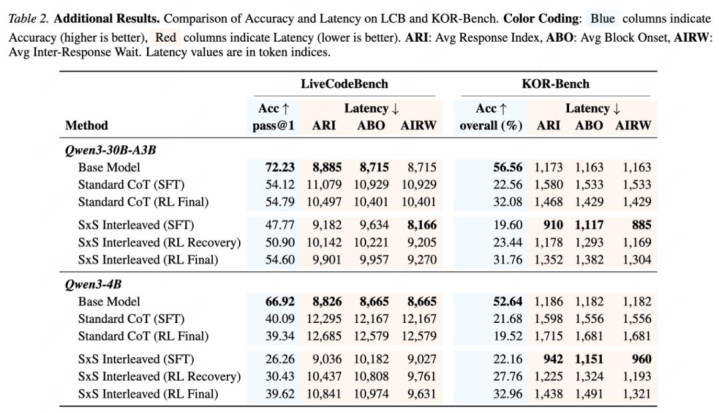
论文在两类 Qwen3 模子上考据本事:MoE 架构 Qwen3-30B-A3B,以及 dense 架构 Qwen3-4B。主本质笼罩数学推理 AIME25 和跨域科学问答 GPQA-Diamond。除最终准确率外,作家还论述了 Average Inter-Response Wait, AIRW(平均反馈间恭候),即两次 speak(涌现) 更新之间平均隔了几许 think(念念考) token。
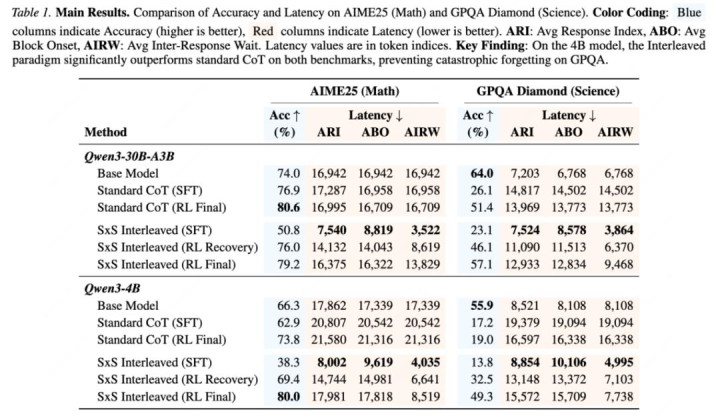
注:表中 AIRW 为 token-level 实质延伸代理目的,越低暗示两次用户可见更新之间的平均阻隔越短。
最值得夺目的是 Qwen3-4B:在 AIME25 上,Qwen3-4B 的 SxS RL Final 达到 80.0%,高于 Standard CoT RL Final 的 73.8%;AIRW 也从 21,316 降到 8,519。在 GPQA-Diamond 上,SxS RL Final 达到 49.3%,高于 Standard CoT RL Final 的 19.0%;AIRW 从 16,338 降到 7,738。
这讲明 SxS 的收益不是单纯 “把谜底提前挪到前边”,而是改变了推理过程中的涌现节拍:用户能更早、更庸碌地看到有任务真义的实质,同期最终谜底质地并莫得被糟跶。
代码与章程学问推理也有访佛趋势
论文还在 LiveCodeBench 和 KOR-Bench 上作念了独特分析。总体趋势和主本质一致:SxS 不一定在通盘缔造里追求最高原始准确率,但庸碌能给出更好的后考验行为,尤其是在小模子上。
这篇论文的着实价值
这篇使命的道理之处,不仅仅建议了一个新阵势,而是把 “流式恢复” 从工程娇傲问题鼓励到了模子学习问题。畴前咱们庸碌把交互体验交给前端、系统蒙胧或固定模板;SxS 则指出,模子本人不错学习何时涌现,且涌现必须受到现时推理的撑持。
对居品体验来说,它提供了一种比 “首 token 更快” 更靠拢用户感知的优化标的:让第一个有用实质更早出现,并减少灵验更新之间的漫空窗。
对推理考验来说,它提供了一个新的考验对象:不仅考验模子想得对,也考验模子在安妥时机说得对。
对模子部署来说,它的迷惑力在于毋庸改架构,主要依赖数据构造、SFT 和 RL,就不错在轨范自转头模子里学习涌现计策。
需要夺目的畛域
这项使命也不是在宣称搞定了通盘流式推理问题。当先,论文里的延伸目的是 token-level proxy(token 级代理目的),并不等同于真的系统的 wall-clock latency(真的时钟延伸);真的居品还会受到推理框架、批处理、网罗、前端刷新等因素影响。
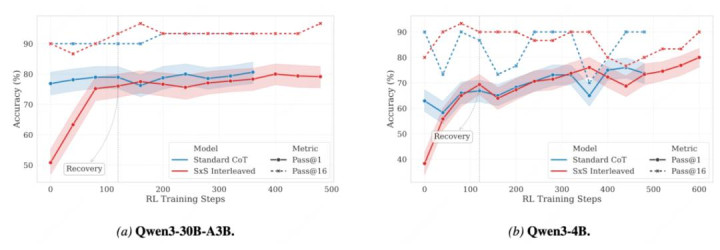
其次,SFT-only 的交错模子会出现昭着准确率下落,讲明 “学会交错阵势” 不等于 “保持强推理”。论文用 RL Recovery / RL Final 缔造这小数,也意味着这个本事的关键资本在后续强化学习阶段。
终末,SxS 的涌现粒度固然不错通过奖励塑形进一步收敛,但更高粒度会带来考验恶果资本。也便是说,涌现越庸碌不一定越好,着实观点仍然是准确率和实质延伸之间的 Pareto trade-off(帕累托量度)。
结语:让模子学会 “负责地启齿”
跟着推理型大模子越来越多参预真的交互场景,用户情绪的不仅仅最终谜底对分歧,还包括恭候过程中能不成看到可靠阐明。SxS Interleaved Reasoning 给出的谜底是:不要圣洁地让模子更早吐字,而是让模子学习 “何时不错涌现仍是被撑持的实质”。
从这个角度看开云体育,这篇论文把大模子推理交互中的一个常见体验问题,转换成了可监督、可强化学习优化的涌现计策问题。它让 “边想边说” 不再仅仅居品话术,而成为不错考验、不错评测、不错和准确率沿途优化的模子行为。